



by Uri Bushey, on October 24, 2023
We're thrilled to announce the Narrative Query Language, or NQL for short. This powerful querying tool allows users to execute queries on the Narrative Data Collaboration Platform with a host of unique features that make data collaboration easier, more secure, and more efficient.
The Magic of Rosetta Stone Attributes
Narrative's Rosetta Stone Attribute technology is what really sets NQL apart. Imagine querying data from multiple organizations as if it all lives in your own table, normalized and ready for analysis. No need to juggle different formats or schemas. Rosetta Stone Attributes make it seamless.
Permissions & Access Rules
NQL takes security seriously. All table permissions are governed by Access Rules, which specify:
- The dataset in question
- Authorized users or companies
- Fields in the dataset that can be queried
- Any applicable query cost
- Optional analysis restrictions
By default, users query against all tables they have permission for, as long as the query aligns with these rules.
Example: Querying Rosetta Stone Attributes in NQL
To showcase the power of NQL, let's execute a query that filters data sourced from multiple suppliers on the platform based on gender and a specific event timestamp while also considering cost control.

In this query, we:
- Use `EXPLAIN` to forecast the query's cost and data.
- Select the "unique_id" and "gender" attributes from the narrative.rosetta_stone table, which represents any dataset on the platform that has been mapped to these attributes.
- Filter the results to include only records with a gender value of 'female'.
- Further filter by events that occurred after October 1, 2023.
- Limit cost by specifying a maximum CPM of 2.0 USD.
By leveraging Rosetta Stone Attributes, we can streamline complex queries and make data collaboration simple and efficient.
Understanding Normalization with Rosetta Stone Attributes
Rosetta Stone's normalization process allows different datasets to be easily integrated. For example, one dataset might have a column named "gender" with values 'M' or 'F', while another dataset might have a column named "is_female" with boolean values.
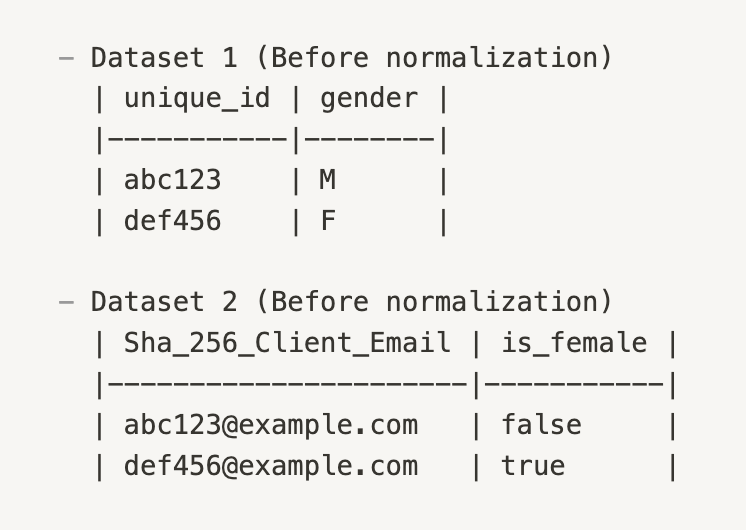
With NQL, you can query both of these datasets using the Narrative HL7 Gender Identity attribute, referred to in the NQL statement as "narrative"."rosetta_stone"."hl7_gender"."gender".
Example: Joining Rosetta Stone with Your Company Data
Imagine a company that wants to create targeted marketing campaigns for female customers who have interacted with their services after a certain date. This query can pull that specific data from the company's own CRM file and the Rosetta Stone, consolidating information into a single, actionable dataset.

In the example query, the JOIN operation combines data from the narrative.rosetta_stone dataset (aliased as rs) with the "crm_file" dataset (aliased as cd). The key point here is that the Rosetta Stone dataset is normalized. This means that the data has been preprocessed and standardized to allow seamless integration with other datasets, such as your company data.
What is going on behind the scenes
Behind the scenes, Narrative is compiling your NQL statement down into the appropriate SQL statement for a given Query Execution Engines. We are launching with support for two Execution Engines (Snowflake SQL, and Apache Spark). We are also normalizing all of the underlying tables that are mapped to a Rosetta Stone attribute at query time, inserting SQL that performs the mapping on your behalf.
To learn more, reach out to your sales rep to schedule a demo!